leads4pass shares the latest and effective MS-600 dumps to help pass the MS-600 exam: “Building Applications and Solutions with Microsoft 365 Core Services“! leads4pass MS-600 Dumps includes MS-600 VCE dumps and MS-600 PDF dumps. leads4pass MS-600 test questions have been updated to the latest date to ensure immediate validity. Get the latest leads4pass MS-600 dumps (PDF + VCE): https://www.leads4pass.com/ms-600.html (100 Q&A dumps)
Get part of MS-600 pdf from Fulldumps for free
Free share Microsoft MS-600 exam PDF from Fulldumps provided by leads4pass
https://www.fulldumps.com/wp-content/uploads/2021/05/lead4pass-Microsoft-365-MS-600-Exam-Dumps-Braindumps-PDF-VCE.pdf
Microsoft MS-600 exam questions online practice test
QUESTION 1
You need to develop a SharePoint Framework (SPFx) solution that interacts with Microsoft SharePoint and Teams. The
solution must share the same code base. What should you include in the solution?
A. Include the Microsoft Authentication Library for .NET (MSALNET) in the solution.
B. Grant admin consent to the Teams API.
C. Make the code aware of the Teams context and the SharePoint context.
D. Publish the solution to an Azure App Service.
Correct Answer: A
QUESTION 2
You are developing a single-page application (SPA).
You plan to access user data from Microsoft Graph by using an AJAX call.
You need to obtain an access token by the Microsoft Authentication Library (MSAL). The solution must minimize
authentication prompts.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
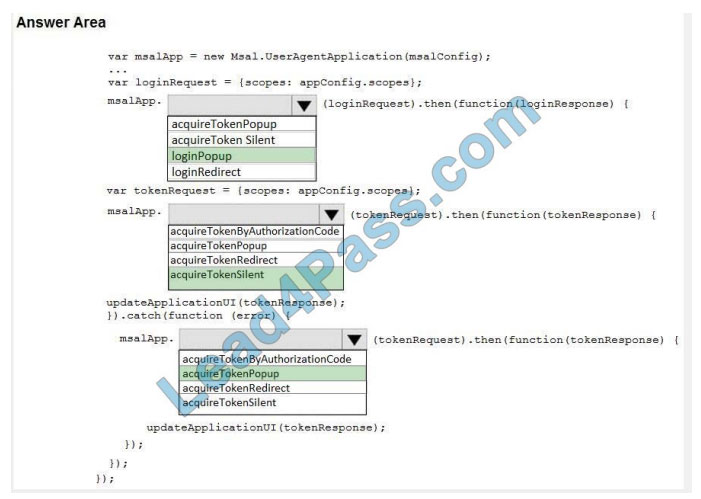
Box 1: loginPopup
Box 2: acquireTokenSilent
The pattern for acquiring tokens for APIs with MSAL.js is to first attempt a silent token request by using the
acquireTokenSilent method. When this method is called, the library first checks the cache in browser storage to see if a
valid token
exists and returns it. When no valid token is in the cache, it sends a silent token request to Azure Active Directory
(Azure AD) from a hidden iframe. This method also allows the library to renew tokens.
Box 3: acquireTokenPopup
//AcquireToken Failure, send an interactive request.
Example:
userAgentApplication.loginPopup(applicationConfig.graphScopes).then(function (idToken) { //Login Success
userAgentApplication.acquireTokenSilent(applicationConfig.graphScopes).then(function (accessToken) {
//AcquireToken Success
updateUI();
}, function (error) {
//AcquireToken Failure, send an interactive request.
userAgentApplication.acquireTokenPopup(applicationConfig.graphScopes).then(function (accessToken) {
updateUI();
}, function (error) {
console.log(error);
});
})
}, function (error) {
console.log(error);
});
Reference: https://github.com/AzureAD/microsoft-authentication-library-for-js/issues/339
QUESTION 3
This question requires that you evaluate the underlined text to determine if it is correct.
You can use a Command Set extension to develop a breadcrumb element that will appear on every Microsoft
SharePoint page.
Instructions: Review the underlined text. If it makes the statement correct, select “No change is needed”. If the
statement is incorrect, select the answer choice that makes the statement correct.
A. No change is needed
B. an Application Customizer
C. a Field Customizer
D. a web part
Correct Answer: B
Application Customizers provide access to well-known locations on SharePoint pages that you can modify based on
your business and functional requirements. For example, you can create dynamic header and footer experiences that
render across all the pages in SharePoint Online.
Reference: https://docs.microsoft.com/en-us/sharepoint/dev/spfx/extensions/get-started/using-page-placeholder-withextensions
QUESTION 4
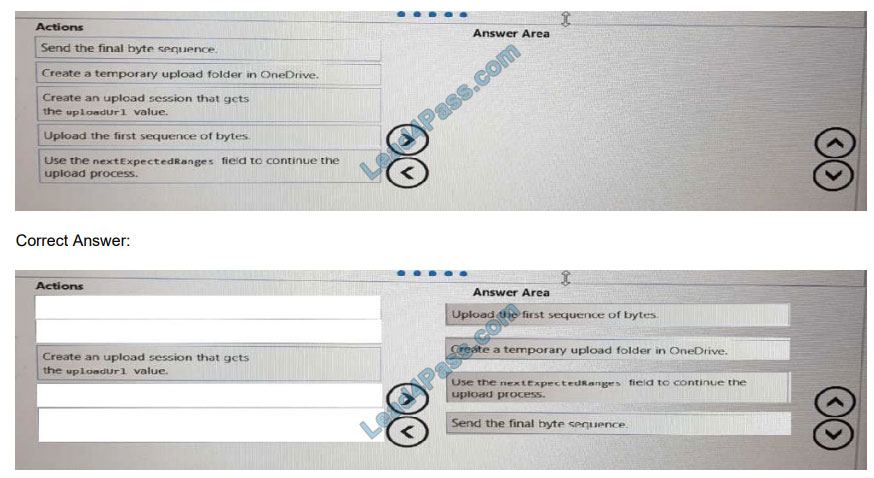
DRAG DROP
You are developing an application that will upload files that are larger than 50 MB to Microsoft OneDrive.
You need to recommend an upload solution to ensure that the file upload process can resume if a network error occurs
during the upload.
Which four actions should you perform in sequence? To answer, move the actions from the list of actions to the answer
area and arrange them in the correct order.
Select and Place:
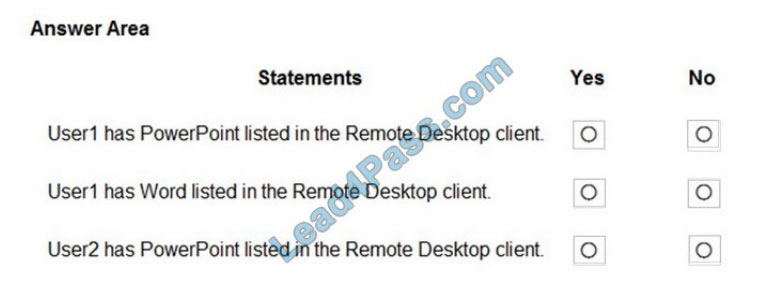
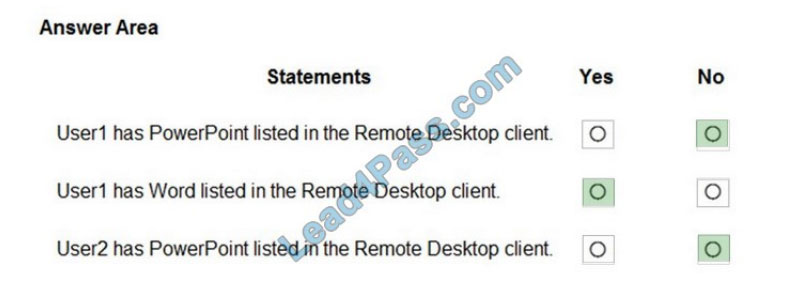
QUESTION 5
You have an application that has the code shown in the exhibits. (Click the JavaScript Version tab or the C# Version
tab.)
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
JavaScript Version 
C# Version

Hot Area:

Correct Answer:
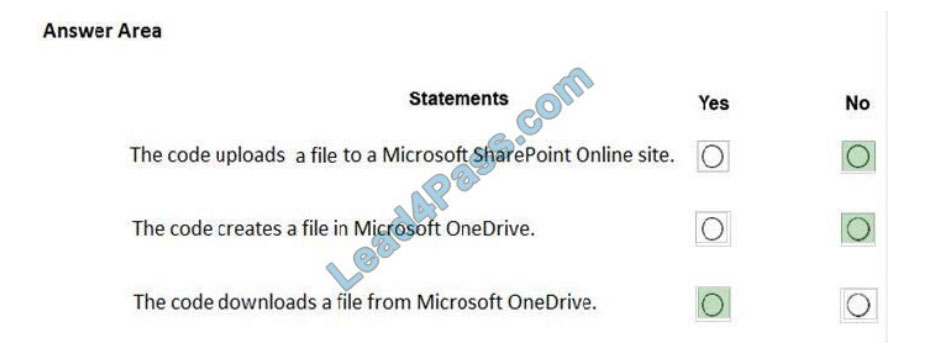
Box 1: No
Box 2: No
Box 3: Yes
A file is downloaded from OneDrive and saved locally.
Drive/Root is the drive resource is the top level object representing a user\\’s OneDrive or a document library in
SharePoint.
Reference: https://docs.microsoft.com/en-us/graph/api/resources/drive
QUESTION 6
DRAG DROP
You are developing a sever-based application that has the following requirements:
Prompt the user to fill out a form that contains a keyword. Search the Microsoft OneDrive folder for files that contain the
keyword and return the results to the user.
Allow the user to select one of the files from the results. Copy the selected file to an Azure Blob storage container.
Which four actions should the application perform in sequence? To answer, move the actions from the list of actions to
the
answer area and arrange them in the correct order.
Select and Place:

QUESTION 7
You have a SharePoint Framework (SPFx) 1.5 solution.
You need to ensure that the solution can be used as a tab in Microsoft Teams.
What should you do first?
A. Convert the solution to use the Bot Framework
B. Deploy the solution to a developer site collection
C. Deploy the solution to the Microsoft AppSource store
D. Upgrade the solution to the latest version of SPFx
Correct Answer: D
Starting with the SharePoint Framework v1.8, you can implement your Microsoft Teams tabs using SharePoint
Framework. Reference: https://docs.microsoft.com/en-us/sharepoint/dev/spfx/web-parts/get-started/using-web-part-asms-teams-tab
QUESTION 8
You have a custom Microsoft Word add-in that was written by using Microsoft Visual Studio Code.
A user reports that there is an issue with the add-in.
You need to debug the add-in for Word Online.
What should you do before you begin debugging in Visual Studio Code?
A. Disable script debugging in your web browser
B. Sideload the add-in
C. Publish the manifest to the Microsoft SharePoint app catalog
D. Add the manifest path to the trusted catalogs
Correct Answer: C
Debug your add-in from Excel or Word on the web
To debug your add-in by using Office on the web (see step 3):
9. Deploy your add-in to a server that supports SSL.
10.In your add-in manifest file, update the SourceLocation element value to include an absolute, rather than a relative,
URI.
11.Upload the manifest to the Office Add-ins library in the app catalog on SharePoint.
12.Launch Excel or Word on the web from the app launcher in Office 365, and open a new document.
13.On the Insert tab, choose My Add-ins or Office Add-ins to insert your add-in and test it in the app.
14.Use your favorite browser tool debugger to debug your add-in.
Reference: https://docs.microsoft.com/en-us/office/dev/add-ins/testing/debug-add-ins-in-office-online
QUESTION 9
You are developing a Microsoft Office Add-in for Microsoft Word. Which Office Ul element can contain commands from
the add-in?
A. dialog boxes
B. the Quick Access Toolbar (QAT)
C. context menus
D. task panes
Correct Answer: A
QUESTION 10
You need to develop a server-based web app that will be registered with the Microsoft identity platform. The solution
must ensure that the app can perform operations on behalf of the user. Which type of authorization flow should you
use?
A. authorization code
B. refresh token
C. resource owner password
D. device code
Correct Answer: A
In web server apps, the sign-in authentication flow takes these high-level steps: You can ensure the user\\’s identity by
validating the ID token with a public signing key that is received from the Microsoft identity platform endpoint. A session
cookie is set, which can be used to identify the user on subsequent page requests.
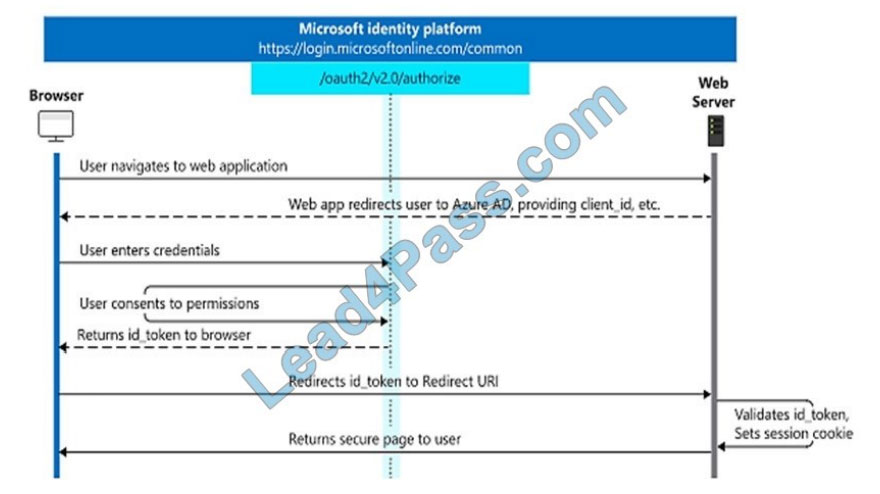
In addition to simple sign-in, a web server app might need to access another web service, such as a REST API. In this
case, the web server app engages in a combined OpenID Connect and OAuth 2.0 flow, by using the OAuth 2.0
authorization code flow. Reference: https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-app-types
QUESTION 11
You company has a third-party invoicing web app.
You need to display the app within Microsoft Teams for one user only. The app will not require conversational
interactions.
How should you display the app by using the minimum amount of effort?
A. Instruct the user to add a website tab
B. Instruct the user to add an App Studio app
C. Create a SharePoint Framework (SPFx) web part
D. Create a search-based messaging extension
Correct Answer: A
There are currently three methods of app integration in Teams: Connectors, Bots, and Tabs. Tabs offer more extensive
integration by allowing you to view entire third-party services within Microsoft Teams. Reference:
https://www.sherweb.com/blog/office-365/o365-microsoft-teams-apps/
QUESTION 12
You need to retrieve a list of the last 10 files that the current user opened from Microsoft OneDrive. The response must
contain only the file ID and the file name.
Which URI should you use to retrieve the results? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
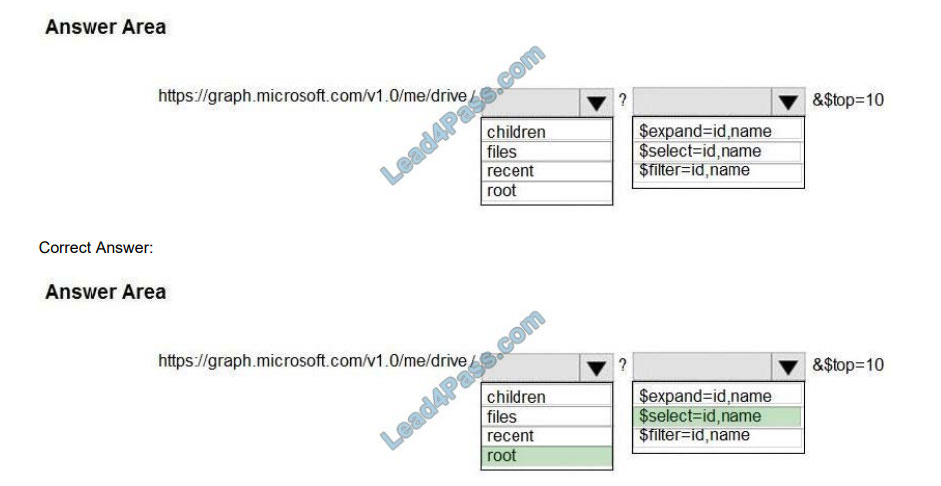
“graph.microsoft.com” “drive” onedrive
Box 1: root
/root – The root folder for the drive.
Box 2: $select=id,name
To specify a different set of properties to return than the default set provided by the Graph, use the $select query option.
The $select option allows for choosing a subset or superset of the default set returned. For example, when retrieving
your messages, you might want to select that only the from and subject properties of messages are returned.
References: https://docs.microsoft.com/en-us/onedrive/developer/rest-api/concepts/addressing-driveitems
https://developer.microsoft.com/en-us/graph/docs/overview/query_parameters
Thank you for reading! I have told you how to successfully pass the Microsoft MS-600 exam.
You can choose: https://www.leads4pass.com/ms-600.html to directly enter the MS-600 Exam dumps channel! Get the key to successfully pass the exam!
Wish you happiness!
Get free Microsoft MS-600 exam PDF online: https://www.fulldumps.com/wp-content/uploads/2021/05/lead4pass-Microsoft-365-MS-600-Exam-Dumps-Braindumps-PDF-VCE.pdf